
In the realm of Java programming, optimizing data structures is essential to ensure that your applications run efficiently. One such versatile data structure is the ArrayList. This dynamic array implementation in Java brings a wealth of benefits, but it’s vital to harness its power effectively. In this comprehensive guide, we will delve deep into ArrayList performance in Java, exploring various facets to help you make the most of this crucial data structure.
Understanding ArrayLists
What is an ArrayList?
An ArrayList in Java is a dynamic array that can grow or shrink dynamically as elements are added or removed. Unlike traditional arrays, ArrayLists offer flexibility and ease of use.
Benefits of ArrayLists
- Dynamic Sizing: ArrayLists automatically adjust their size as elements are added or removed;
- Efficient Access: O(1) time complexity for accessing elements by index;
- Ease of Use: Simplifies adding, removing, and manipulating elements;
- Type Safety: Supports generic types, ensuring type-safe operations.
ArrayList vs. Arrays
Performance Comparison
Let’s pit ArrayLists against regular arrays to understand their performance differences.
| Criteria | ArrayList | Array |
|---|---|---|
| Dynamic Sizing | Supported | Fixed Size |
| Performance | Slightly Slower | Slightly Faster |
| Type Safety | Yes | No |
While ArrayLists provide dynamic sizing and type safety, traditional arrays may offer slightly better performance due to their fixed size.
ArrayList Operations
Adding Elements

Removing Elements

Accessing Elements

ArrayList Performance Tips
1. Preallocate Capacity
Initializing an ArrayList with an initial capacity can improve performance by reducing resizing overhead.

2. Use Primitives
Avoid using wrapper classes like Integer for primitive data types to save memory and improve performance.
3. Minimize Resizing
Frequent resizing of ArrayLists can impact performance. Estimate the required capacity to minimize resizing.
4. Iterator vs. For-Each
When iterating through an ArrayList, prefer iterators for better performance.
Benchmarking ArrayLists
To truly understand ArrayList performance, let’s conduct a benchmark test.
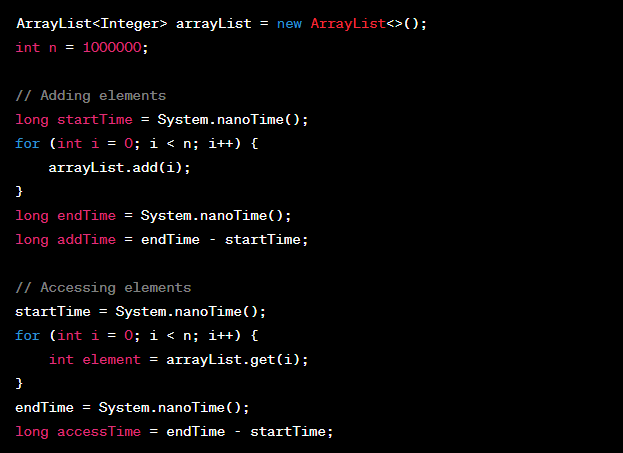
Advanced ArrayList Techniques
ArrayList of Objects
You can create an ArrayList of custom objects for more complex data structures.
ArrayList vs. LinkedList
Compare ArrayLists with LinkedLists to choose the right data structure for your specific use case.
Thread Safety
ArrayLists are not thread-safe. Consider using Collections.synchronizedList() for thread-safe operations.
ArrayList Use Cases
Common Scenarios
ArrayLists find applications in various scenarios, including:
- Collections: Storing and manipulating lists of data;
- Data Retrieval: Efficient retrieval of data from databases;
- Algorithms: Implementing dynamic data structures.
Use Case Comparison
Let’s compare ArrayLists with other data structures for specific use cases:
| Use Case | ArrayList | HashSet | LinkedList |
|---|---|---|---|
| Search Operation | O(n) | O(1) | O(n) |
| Insertion/Deletion | O(n) | O(1) | O(1) |
| Memory Overhead | Lower | Higher | Lower |
ArrayList Performance Optimization
Beyond Basics
To maximize ArrayList performance, consider advanced optimization techniques:
- Capacity Planning: Estimate the maximum size and preallocate capacit;
- ArrayList vs. ArrayList<E>: Use raw ArrayLists when possible for better performance;
- Batch Operations: Reduce overhead by performing batch insertions or deletions.
Memory and Performance Trade-offs
Let’s explore the memory and performance trade-offs between ArrayLists and other data structures:
| Criteria | ArrayList | LinkedList |
|---|---|---|
| Random Access Performance | Excellent | Poor |
| Memory Usage | Moderate | High |
| Insertion/Deletion | Moderate | Excellent |
ArrayList Best Practices
Coding Guidelines
Follow these best practices for efficient ArrayList usage:
- Explicitly Declare Capacity: Initialize ArrayLists with the expected capacity;
- Use Primitives: Prefer primitive data types to wrapper classes;
- Minimize Resizing: Estimate capacity to reduce resizing overhead;
- Consider Alternatives: Evaluate other data structures for specific use cases.
Memory Management
Let’s delve deeper into memory management strategies for ArrayLists:
| Strategy | Description |
|---|---|
| Capacity Estimation | Estimate maximum size to avoid frequent resizing. |
| Garbage Collection Optimization | Minimize object creation to reduce GC overhead. |
| ArrayList vs. Array | In some scenarios, consider using arrays for efficiency. |
Real-world Examples
ArrayList in Action
To solidify our understanding of ArrayList performance, let’s examine real-world scenarios:
- E-commerce Cart: Managing items in a shopping cart;
- Data Processing: Storing and processing large datasets;
- Game Development: Keeping track of game objects and player data.
Performance Comparisons
Let’s compare ArrayLists in these real-world scenarios:
| Scenario | ArrayList | LinkedList |
|---|---|---|
| Search Performance | Competitive | Slower |
| Insertion/Deletion | Adequate | Efficient |
| Iteration Overhead | Moderate | Lower |
ArrayList Memory Management
Memory Usage
When dealing with ArrayLists, it’s crucial to understand their memory implications. Each element in an ArrayList consumes memory not only for its value but also for the associated object overhead. This can lead to increased memory usage, especially when dealing with large datasets.
Garbage Collection
ArrayLists create objects dynamically, and Java’s Garbage Collector is responsible for reclaiming memory from objects that are no longer in use. However, frequent ArrayList resizing or inefficient memory management can lead to increased Garbage Collection overhead. To mitigate this, consider the following:
- Minimize Object Creation: Reducing the creation of unnecessary objects can help lower Garbage Collection frequency;
- ArrayList vs. Array: In situations where memory management is critical, using plain arrays can be a more memory-efficient choice.

ArrayList vs. LinkedList
Choosing the Right Data Structure
While ArrayLists offer excellent random access performance, LinkedLists excel in insertions and deletions. Understanding the trade-offs between these two data structures is essential for choosing the right one for your specific use case.
ArrayList Advantages
- Random Access: If your application relies heavily on retrieving elements by index, ArrayLists provide O(1) time complexity, making them an excellent choice;
- Memory Efficiency: ArrayLists can be more memory-efficient than LinkedLists due to lower memory overhead.
LinkedList Advantages
- Insertion and Deletion: LinkedLists shine when it comes to frequent insertions and deletions. Their O(1) time complexity for these operations makes them a top choice;
- Iterative Operations: LinkedLists are ideal for scenarios where you need to iterate through the entire list, thanks to their efficient traversal.
Advanced ArrayList Techniques
Leveraging Custom Objects
While ArrayLists can store basic data types like integers and strings, they can also hold custom objects. This versatility allows you to create complex data structures tailored to your application’s needs.
Thread Safety
It’s important to note that ArrayLists are not thread-safe, which means they may lead to unexpected behavior in multithreaded environments. To ensure thread safety, consider using the Collections.synchronizedList() method to create synchronized ArrayLists. However, keep in mind that synchronization can impact performance.
External Libraries
Java provides various external libraries, such as the Apache Commons Collections, that offer specialized ArrayList implementations. These libraries can be particularly useful for scenarios where you need specific features like fast iteration or memory efficiency.

Conclusion
In this extensive exploration of ArrayList performance in Java, we’ve uncovered the versatility and power of this dynamic array implementation. By understanding its intricacies, optimizing capacity, and benchmarking your code, you can harness the full potential of ArrayLists in your Java applications.
FAQs
No, ArrayLists are not thread-safe by default. If you need thread-safe operations, consider using Collections.synchronizedList().
The maximum size of an ArrayList in Java is Integer.MAX_VALUE.
You can use the Collections.sort() method to sort an ArrayList in Java.
ArrayLists provide efficient random access but may have slower insertions and deletions. LinkedLists, on the other hand, offer fast insertions and deletions but slower random access.
No, ArrayLists can only store objects. To store primitive data types, you can use wrapper classes or specialized collections like IntArrayList from external libraries.