
In today’s digital landscape, where speed and efficiency are paramount, optimizing the performance of your applications is non-negotiable. Data encoding and decoding operations, such as Base64 encoding and decoding, are integral to various facets of software development. In this comprehensive guide, we will delve deep into Base64 encoding and decoding, exploring their significance, the inner workings, and best practices to supercharge their performance. By the end of this article, you’ll be equipped with the knowledge to turbocharge your applications when working with Base64-encoded data.
Understanding Base64 Encoding
What is Base64 Encoding?
Base64 encoding is a fundamental technique used in computer science and information technology to convert binary data into a sequence of ASCII characters. This method provides a means to represent binary data, which primarily consists of 0s and 1s, using a set of 64 different printable characters. Unlike raw binary data, which is inherently challenging to transmit and display in text-based environments, Base64-encoded data is easily portable and readable by humans, making it an invaluable tool in a wide array of applications.
Use Cases and Importance
The significance of Base64 encoding spans across various digital domains. Its versatility and practicality have led to its widespread adoption in countless scenarios. For instance, in web development, Base64 encoding is employed to embed images within HTML documents, allowing for seamless rendering of visual content on web pages. In the realm of electronic communication, it plays a pivotal role in encoding binary attachments, enabling the transmission of files via email or other text-based protocols. Furthermore, Base64 encoding is used to store complex data structures within JSON (JavaScript Object Notation) files, facilitating the interchange of structured data between applications and systems. In essence, understanding Base64 encoding is not just a technical detail but a fundamental skill for anyone working with data in today’s interconnected digital landscape.
How Base64 Encoding Works
Base64 encoding operates on a simple yet ingenious principle. It takes groups of three 8-bit binary bytes (a total of 24 bits) and transforms them into four 6-bit characters, resulting in a string that is both human-readable and safe for transmission within text-based formats. This transformation involves a mapping of binary values to a predefined set of 64 ASCII characters, typically consisting of uppercase and lowercase letters, digits, and two additional characters, often ‘+’ and ‘/’. By segmenting data into 24-bit chunks and encoding them into 6-bit units, Base64 ensures that the output remains within the realm of ASCII characters, making it compatible with a wide range of systems and protocols. This elegant encoding scheme has become a cornerstone of data interchange, allowing binary data to seamlessly integrate with text-based environments while preserving data integrity and readability.
The Decoding Process
The intricate dance between data transformation and preservation continues with the decoding process. Decoding, the counterpart to encoding, serves the crucial role of unraveling Base64-encoded data and reverting it to its original binary form. Much like encoding, decoding is a fundamental operation in the realm of data manipulation and is indispensable for accessing, understanding, and utilizing data that has been encoded in the Base64 format.
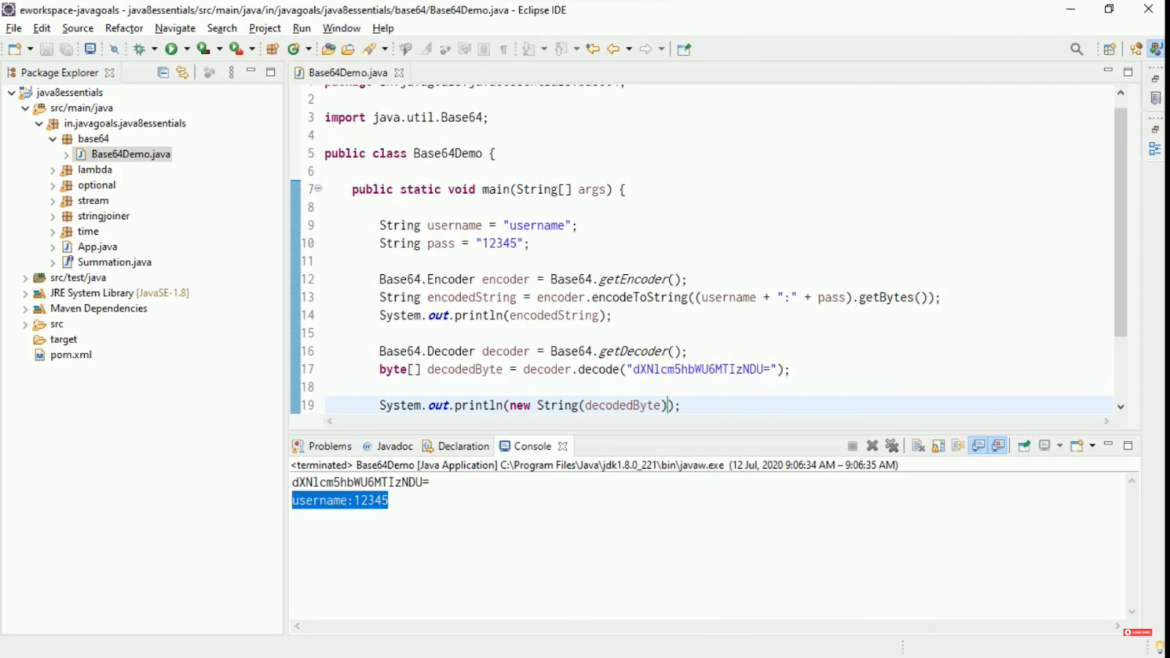
- Mechanics: Decoding Base64 is the meticulous reversal of encoding steps, transforming Base64-encoded data back into its original binary form. It involves breaking the encoded string into groups of four characters, each representing six bits. These six-bit values are converted back to eight-bit binary, faithfully reconstructing the original data. This methodical process ensures accurate data recovery;
- Relevance in Data Retrieval: Decoding Base64 data is crucial in practical scenarios, especially in web development. For instance, web browsers must decode Base64-encoded images retrieved from remote servers before displaying them to users. This practical application highlights the importance of decoding in facilitating seamless data retrieval and presentation;
- Common Use Cases: Decoding Base64 data has widespread utility. Email clients regularly decode Base64-encoded attachments for easy file access. In web services and REST APIs, decoding is essential for processing incoming data, making information usable. Additionally, network protocols often rely on Base64 decoding to manage binary data in a text-based context. Mastering Base64 decoding is not just a valuable skill but an essential tool for navigating data manipulation and transmission in the digital world.
Performance Considerations
The quest for peak performance in Base64 operations goes beyond a mere desire for speed; it’s an imperative born out of necessity. In the ever-evolving landscape of modern computing, where efficiency reigns supreme, optimizing the encoding and decoding of Base64 data is not a luxury but a strategic imperative. It wields the potential to exert a profound influence on the responsiveness of high-throughput applications and the overall quality of the user experience. In this context, performance isn’t just an aspiration; it’s an essential factor that can spell the difference between success and mediocrity.
Why Performance Matters
In today’s digital landscape, the significance of performance in Base64 operations cannot be overstated. In data-intensive environments like cloud services, web applications, and compute-intensive tasks, the speed of Base64 encoding and decoding operations can be the deciding factor for success. Accelerated encoding and decoding directly translate to reduced response times, elevating user satisfaction and engagement. Whether it’s a swift-loading web page, seamless video streaming, or a cloud application seamlessly managing numerous requests, the efficiency of Base64 operations is pivotal in shaping overall performance and success.
Benchmarking Base64 Operations
Before delving into the optimization journey, gaining insight into the current state of Base64 operations is essential. Benchmarking serves as a vital tool for this purpose. It entails subjecting encoding and decoding routines to rigorous testing across various scenarios and workloads. Through benchmarking, not only is a performance baseline established, but valuable insights into the strengths and weaknesses of existing implementations are unearthed. These insights provide a solid foundation upon which optimization strategies can be crafted and assessed.
Identifying Bottlenecks
Achieving optimal performance in Base64 operations mirrors the complexity of solving a intricate puzzle. The initial step towards unlocking speed and efficiency involves identifying performance bottlenecks that impede progress. These bottlenecks can manifest in diverse forms, such as excessive CPU utilization, suboptimal memory allocation, or inefficient I/O operations. Pinpointing these performance bottlenecks is akin to spotlighting critical areas requiring enhancement. It serves as the compass guiding the optimization journey towards smoother, faster, and more efficient Base64 operations. Ultimately, this process enhances the overall performance of applications and systems by focusing efforts on areas with the highest potential for performance gains.
Techniques for Base64 Encoding Optimization
- Utilizing Hardware Acceleration: Modern CPUs often include hardware instructions for Base64 operations, which can significantly speed up encoding and decoding. Utilizing these instructions can be a game-changer for performance;
- Parallel Processing: In scenarios where you have multiple Base64 operations to perform, parallel processing can distribute the workload across multiple cores or threads, reducing processing time;
- Minimizing Memory Usage: Base64 operations can consume a significant amount of memory, especially for large data sets. Minimizing memory usage through efficient data structures and algorithms is key to optimization;
- Choosing the Right Encoding Library: Not all Base64 encoding libraries are created equal. Choosing a well-optimized and well-maintained library can make a substantial difference in performance.
Strategies for Base64 Decoding Optimization
When it comes to Base64 decoding, a multitude of strategies can be employed to enhance performance and streamline the process. In the dynamic world of data transformation, where speed and efficiency reign supreme, these optimization techniques play a pivotal role in ensuring that your applications and systems perform at their best.
Caching Mechanisms
Caching is a potent method for optimizing Base64 decoding. It involves storing previously decoded Base64 data results, enabling rapid retrieval when needed again. This approach is particularly effective for scenarios where the same data is frequently decoded, eliminating the need to recompute the decoding process from scratch. By harnessing caching, processing time is significantly reduced, resulting in a more responsive and efficient data processing pipeline. Think of it as maintaining a well-organized library where frequently accessed books are readily available, saving valuable time and effort.
Prefetching Data
In situations involving data streams, prefetching is a valuable tool to reduce latency. Prefetching involves proactively fetching and decoding data ahead of its actual use. By anticipating data requirements and preparing it in advance, the delays associated with on-demand decoding are eliminated. This technique is especially advantageous in applications where data retrieval must be time-sensitive, and waiting for data to decode on-the-fly would introduce unacceptable latency. Prefetching ensures that the necessary data is immediately accessible, fostering smoother and more responsive data processing.
Efficient Error Handling
Error handling is a critical aspect of robust software systems but can introduce performance overhead in Base64 decoding. Implementing efficient error-handling mechanisms is crucial to mitigate this potential impact. By employing error-handling routines optimized for speed and precision, the overhead associated with error checking and reporting is minimized. This not only enhances the overall efficiency of Base64 decoding operations but also ensures that error handling remains an asset rather than a hindrance to performance.
Choosing the Right Decoding Library
Much like in Base64 encoding, the selection of the appropriate decoding library can be a game-changer in the optimization journey. Opting for a decoding library designed for performance and equipped with robust error-handling mechanisms can make a significant difference. These libraries are often fine-tuned to leverage hardware acceleration when available, maximizing the efficiency of decoding processes. Choosing the right library is akin to picking the ideal tool for the task, enabling your applications and systems to fully harness the potential of Base64 decoding while maintaining peak performance.
Real-World Case Studies

The practical applications of Base64 encoding and decoding extend far and wide, with real-world case studies showcasing the tangible benefits of optimization. Across industries and digital domains, these case studies illuminate the transformative power of streamlined Base64 operations in enhancing performance, user experience, and efficiency.
| Case Study | Description and Impact |
|---|---|
| Netflix: Optimizing Video Streaming | Netflix utilizes Base64 encoding and decoding to enhance the efficiency of its data transmission, directly impacting streaming quality and load times for an improved viewer experience. |
| Cloud Storage Providers: Data Retrieval Efficiency | Cloud storage providers leverage Base64 optimization to ensure fast and reliable data retrieval, catering to the needs of users and developers accessing files and assets. |
| Web Browsers: Faster Page Loading | Web browsers employ Base64 optimization to speed up page loading times, resulting in improved user satisfaction, longer session durations, and an overall enhanced browsing experience. |
Conclusion
In the fast-paced world of software development, optimizing Base64 encoding and decoding operations is a crucial step toward delivering efficient and responsive applications. By understanding the mechanics of Base64, identifying performance bottlenecks, and implementing the right optimization techniques, you can ensure that your applications operate at peak efficiency, providing users with the best possible experience in a digital world that demands speed and performance.