Java, a multifaceted and object-oriented programming language, empowers developers to deftly maneuver infodata across diverse formats through an array of I/O streams and utilities. Two pivotal entities that find extensive application in the realm of data input management include the BufferedInputStream hailing from Java’s IO suite and the GzipInputStream nestled within the zip package of Java Util. These class components hold paramount importance in the seamless extraction of information, notably excelling in the orchestration of compressed file handling, thereby amplifying the efficiency of I/O operations.
Unlocking the Power of Java IO: BufferedInputStream
In the vast landscape of Java’s Input/Output functionality, BufferedInputStream emerges as a remarkable tool, tucked away in the java.io package. This unassuming class plays a pivotal role in optimizing data reading operations, breathing new life into your applications. Let’s dive deep into its capabilities, functionality, and tips for harnessing its full potential.
Enhancing Data Read Operations
At its core, BufferedInputStream is a master of efficiency. It acts as a guardian for input streams, shielding your application from the overhead of frequent access to the info source. Here’s how it works its magic:
- Internal Buffering: BufferedInputStream creates an internal buffer, essentially a data reservoir. Instead of fetching data byte by byte from the source, it reads chunks of data into this buffer. This ingenious approach minimizes the number of read operations, thus reducing the I/O cost significantly.
Getting Started
Now that you’re eager to wield the power of it, let’s see how you can put it to use:
Initialization: To begin, you’ll want to create an instance of BufferedInputStream. It’s a simple one-liner, as shown below:
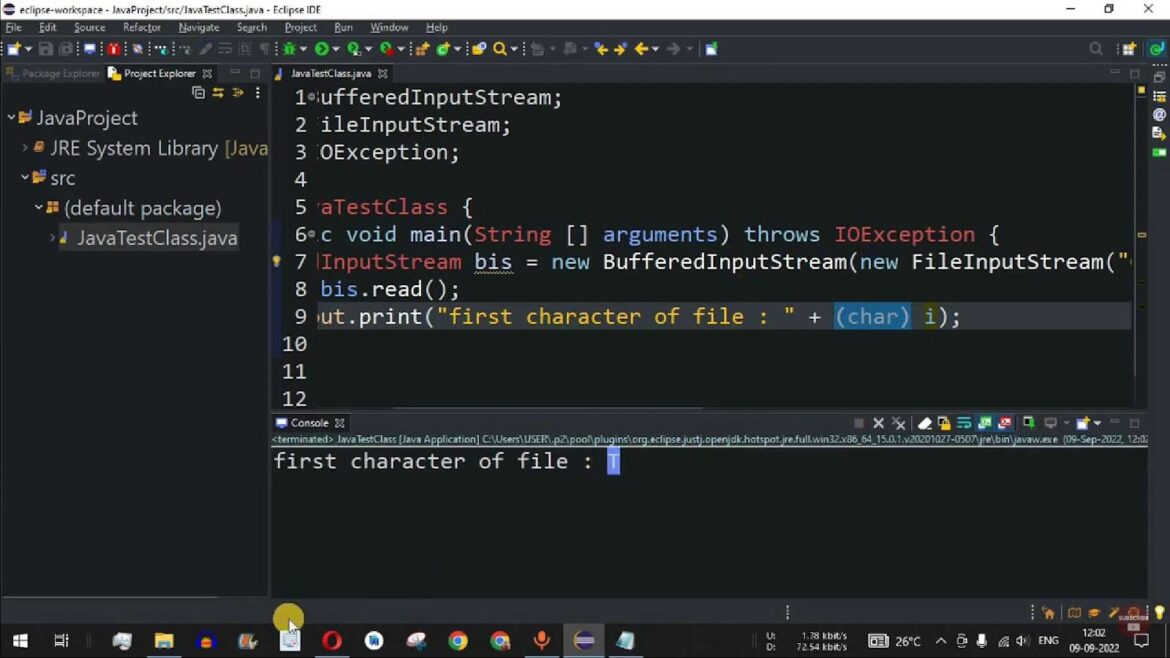
InputStream buffer = new BufferedInputStream(new FileInputStream(“filename.txt”));
This line wraps your file input stream with the buffering capabilities of BufferedInputStream.
Supercharging Performance
BufferedInputStream doesn’t just stop at mere buffering; it’s all about supercharging your application’s performance:
Reduced I/O Calls: By slashing the number of calls made to the underlying input stream, BufferedInputStream trims down the time spent on system-level I/O operations. It stores more data in its internal buffer during each call, and subsequent reads tap into this goldmine of data. This procedure dramatically boosts performance, especially when dealing with sluggish data sources or network connections.
Tailoring Buffer Sizes to Your Needs
Here’s where it truly shines – customization. It allows developers to fine-tune the buffer size to align with the specific demands of their applications:
Bespoke Buffer Sizes: When it comes to buffer size, you have the liberty to choose. A larger buffer size can be a game-changer for reading mammoth-sized files or when you’re on a mission to squeeze every ounce of performance. On the flip side, if conserving memory is paramount, a smaller buffer size is your go-to choice.
Expert Tips for Optimal Usage
- Benchmark: Experiment with different buffer sizes to find the sweet spot for your application. Profiling tools can help identify the ideal buffer size for your specific use case;
- Wrap It Right: Ensure that you wrap BufferedInputStream around the appropriate input stream, whether it’s a FileInputStream for local files or a network stream for remote data sources;
- Exception Handling: Always implement robust error handling. It can throw exceptions, so be prepared to catch and handle them gracefully.
GzipInputStream – Your Gateway to Efficient Data Compression and Decompression
Functionality and Usage
At the core of GzipInputStream lies its ability to read compressed data and swiftly decompress it on-the-fly. It serves as a filter, seamlessly integrating with other input streams.
Here’s how it works:
Wrap and Read: When your application needs to access compressed data, you simply wrap a GzipInputStream around another input stream. It does the heavy lifting by reading and decompressing the data in real-time, giving your application access to the uncompressed data. Consider this basic example:
InputStream gzipStream = new GzipInputStream(new FileInputStream(“filename.gz”));
Error Handling: Remember to include robust error handling in your code to gracefully handle exceptions and edge cases, ensuring your application’s reliability.
Data Decompression: Squeezing Out Efficiency
The primary mission of GzipInputStream is to handle GZIP-compressed data, converting it back to its original form. This capability becomes invaluable in scenarios where data efficiency is paramount, especially in network communications. By compressing data before transmission and decompressing it upon receipt, you can:
- Reduce Bandwidth: Transmit less data, saving bandwidth and costs;
- Enhance Performance: Faster transmission and reduced latency.
Integrating with BufferedInputStream: A Performance Boost
To turbocharge your data processing, consider coupling GzipInputStream with BufferedInputStream. This combination introduces the advantages of buffered reading alongside real-time decompression. Here’s a simplified example:
- InputStream combinedStream = new BufferedInputStream(new GzipInputStream(new FileInputStream(“filename.gz”)));
By implementing this approach, you can further optimize your application’s performance when handling compressed data.
Application in Network Communications: A Game Changer
GzipInputStream isn’t just a tool; it’s a game-changer in network communications and various applications where data transmission efficiency is paramount. Here’s how it fits in:
- Efficient Data Transmission: GzipInputStream reduces the amount of data transmitted, conserving precious bandwidth;
- Web Servers: It’s an integral part of many web servers, ensuring fast and efficient content delivery;
- Latency Reduction: By transmitting less data, it reduces latency, making user experiences smoother.
Conclusion
In the realm of Java programming, both the BufferedInputStream and GzipInputStream classes play pivotal roles, each possessing unique capabilities when it comes to managing and manipulating data. BufferedInputStream excels at enhancing read operations by intelligently buffering data, thereby mitigating the high I/O costs typically associated with frequent read requests. In contrast, the GzipInputStream shines as an indispensable tool for deciphering compressed data, particularly in situations where bandwidth is a precious resource.
Comprehending the inner workings and practical applications of these streams is imperative for developers striving to optimize data reading processes and proficiently handle compressed data. When judiciously combined, these two streams can wield a substantial influence on the performance and effectiveness of applications across diverse domains. This synergy is especially advantageous when dealing with vast datasets and communication over networks.
By harnessing the power of these streams in a judicious manner, developers can ensure the utmost efficiency in resource utilization and overall application performance within the Java ecosystem. This strategic utilization paves the path for the creation of more resilient and proficient software solutions.