
In the ever-evolving landscape of data management, Java Protobuf stands out as a powerful tool for efficient data encoding and decoding. This article delves deep into the world of Java Protobuf, focusing specifically on its handling of numeric datatypes. Whether you’re a seasoned developer or just getting started, this comprehensive guide will equip you with the knowledge to handle numeric data like a pro.
The Basics of Java Protobuf
What Is Java Protobuf?
Java Protobuf, short for Protocol Buffers, is a language-agnostic data serialization format developed by Google. It allows you to define structured data schemas and efficiently encode and decode data in a compact binary format.
Why Choose Java Protobuf?
- Efficiency: Java Protobuf offers a highly efficient binary serialization format, making it ideal for transmitting and storing data;
- Interoperability: Since Protobuf is language-agnostic, you can use it across different programming languages;
- Schema Evolution: Protobuf supports schema evolution, allowing you to add or remove fields without breaking compatibility.
Numeric Datatypes in Java Protobuf
Understanding Varint Encoding
Java Protobuf employs a technique known as varint encoding for numeric datatypes. Varints are variable-length integers that optimize space usage. They use fewer bytes to represent smaller values and more bytes for larger values, reducing the overall data size.
Handling Integer Datatypes
int32 and int64
int32 and int64 datatypes are used to represent signed integers in Java Protobuf.
Example:

Floating-Point Datatypes
float and double
float and double datatypes are used to represent floating-point numbers.
Example:

Enumerations
Enumerations are a powerful way to represent numeric options in Java Protobuf. They map a set of named values to integers, providing better readability and type safety.

Advanced Techniques
Default Values
In Java Protobuf, you can specify default values for fields. This ensures that missing fields have a meaningful default value when decoding data.
Encoding Efficiency Tips
- Use varint encoding for smaller numeric values to save space.
- Consider using packed encoding for repeated numeric fields to improve efficiency.
Comparing Java Protobuf with JSON and XML
When it comes to numeric data encoding, Java Protobuf offers distinct advantages over JSON and XML:
| Feature | Java Protobuf | JSON | XML |
|---|---|---|---|
| Binary Format | Yes | No | No |
| Schema Evolution | Supported | Limited | Limited |
| Space Efficiency | High | Low | Low |
| Interoperability | Yes | Yes | Yes |
Code Snippet
Here’s a Java code snippet demonstrating how to encode and decode numeric data using Java Protobuf:
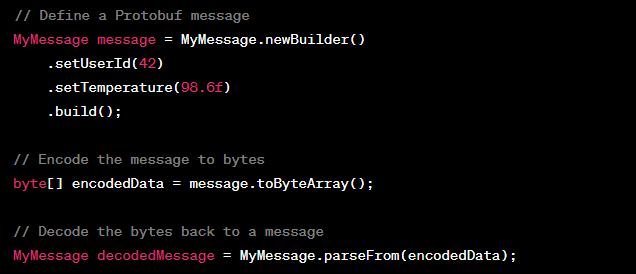
Efficient Numeric Data Management
Java Protobuf’s efficiency in handling numeric datatypes is unparalleled. By leveraging varint encoding, default values, and other advanced techniques, you can optimize your data storage and transmission processes. Say goodbye to bloated data formats and embrace the power of Java Protobuf.

Efficient Numeric Data Transmission
When it comes to transmitting numeric data, Java Protobuf’s efficiency truly shines. By minimizing data size through varint encoding, it significantly reduces the bandwidth required for data transfer. This not only results in faster data transmission but also leads to cost savings, especially in scenarios where network bandwidth is a critical resource.
Here’s a list of key benefits and strategies for efficient numeric data transmission using Java Protobuf:
- Reduced Bandwidth Usage: Varint encoding reduces the size of numeric data, leading to decreased network usage;
- Faster Data Transfer: Smaller data payloads mean faster transmission, improving overall system performance;
- Cost-Efficient: Lower bandwidth requirements translate into cost savings, particularly in cloud-based applications.
Handling Enumerations in Java Protobuf
Enumerations provide a structured way to handle numeric options within Java Protobuf. They are not just limited to gender options, as mentioned earlier, but can be used for a wide range of scenarios. Let’s explore some examples:
- Status Codes: Enumerations can be used to define a set of status codes for a network protocol or an application, making it easier to interpret responses;
- Error Types: You can use enums to define error types, making error handling more systematic and concise;
- Event Types: In event-driven systems, enumerations help define various event types for better event processing.
Here’s an example of how to define an enumeration in a .proto file:
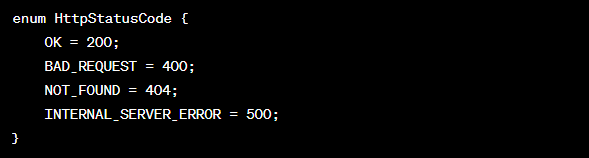
Handling Large Numeric Values
In some applications, especially those dealing with scientific or financial data, you may encounter the need to handle extremely large numeric values. Java Protobuf provides a convenient way to manage such values without losing precision.
Consider the scenario where you need to work with large integers or floating-point numbers with high precision. Java Protobuf allows you to use the string datatype to store and transmit these values without any loss of accuracy.
For example, you can define a message like this:

This approach ensures that even the most substantial numeric data remains accurate during encoding and decoding.
Real-World Applications of Java Protobuf for Numeric Data
Java Protobuf’s numeric data encoding capabilities find applications in a wide range of industries and use cases. Here are some real-world examples:
1. Financial Services
In the world of finance, precision and efficiency are paramount. Java Protobuf’s ability to handle numeric data with minimal overhead makes it a preferred choice for transmitting market data, portfolio information, and financial transactions.
2. Scientific Research
Scientific experiments often produce large datasets with complex numeric values. Researchers benefit from Java Protobuf’s precision when transmitting and storing critical data for analysis and collaboration.
3. IoT and Sensor Networks
IoT devices and sensor networks generate massive amounts of numeric data. Java Protobuf’s compact binary format ensures that sensor readings and telemetry data can be efficiently transmitted and stored, optimizing resource utilization.
4. Gaming and Virtual Reality
In the gaming industry, where real-time data exchange is crucial, Java Protobuf’s efficiency shines. It’s used to transmit player positions, game state information, and scores, ensuring a seamless gaming experience.

Conclusion
In this comprehensive guide, we’ve explored the intricacies of Java Protobuf data encoding for numeric datatypes. You’ve learned about varint encoding, handling integer and floating-point datatypes, and advanced techniques to enhance efficiency. By choosing Java Protobuf, you’re making a smart choice for streamlined data management.
FAQs
Java Protobuf offers superior space efficiency and supports schema evolution, making it an ideal choice for numeric data encoding.
Varint encoding uses a variable-length format to represent integers, optimizing space usage by using fewer bytes for smaller values.
Yes, Java Protobuf is language-agnostic, allowing you to use it across different programming languages.
Use varint encoding for smaller values, consider packed encoding for repeated fields, and specify default values for fields.
Java Protobuf outperforms JSON and XML in terms of space efficiency, schema evolution support, and overall binary format.