
If you’re diving into the world of Java programming, understanding how string intern works in Java 6, 7, and 8 is crucial. String intern is a memory optimization technique that can significantly impact the performance of your Java applications. In this comprehensive guide, we’ll explore everything you need to know about string intern and how to harness its power to write more efficient code.
What is String Interning?
String interning is the process of storing only one copy of each distinct string value in a common pool. When a new string is created, Java checks if an identical string already exists in the pool. If it does, the new string references the existing one, saving memory.
Why is String Interning Important in Java?
String intern plays a critical role in Java’s memory management. It’s particularly valuable when dealing with large datasets, caching, or frequently used string values.
String Intern in Java 6
In Java 6, string interning follows a straightforward mechanism. When you create a string using double quotes, Java automatically interns it.
How String Interning Works in Java 6
For instance, consider the following code snippet:
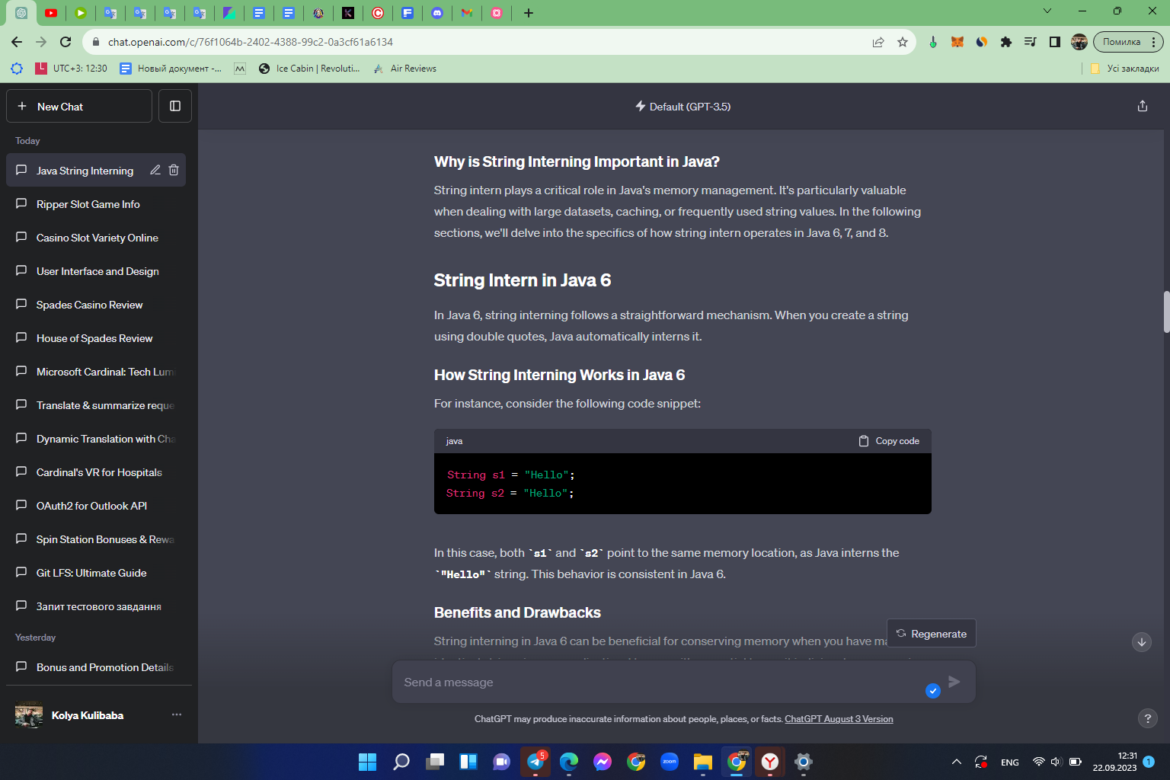
In this case, both s1 and s2 point to the same memory location, as Java interns the “Hello” string. This behavior is consistent in Java 6.
Benefits and Drawbacks
String interning in Java 6 can be beneficial for conserving memory when you have many identical strings in your application. However, it’s essential to use it judiciously, as excessive string intern usage can lead to increased memory consumption.

String Intern in Java 7
Java 7 introduced improvements to string interning, enhancing both performance and predictability.
Improvements in Java 7
In Java 7, string interning uses a more efficient data structure, making it faster and more reliable. Additionally, you can manually intern strings using the intern() method.
Performance Enhancements
Java 7’s string interning is better suited for multithreaded applications, as it reduces contention for string pool access. It’s a significant step forward in optimizing memory management.
String Intern in Java 8
Java 8 continued the evolution of string interning, introducing changes and enhancements to further improve performance.
Changes and Enhancements
In Java 8, the string pool is moved from the PermGen space to the main heap, making it more scalable. This change addresses some of the issues with string intern in earlier versions.
Best Practices
Java 8 encourages the use of string intern in scenarios where it genuinely improves performance. However, it’s crucial to measure the impact on your specific application to ensure optimal results.
String Pool vs. Heap
To understand string intern better, it’s essential to grasp the difference between the string pool and the heap memory.
Understanding String Pool and Heap Memory
The string pool is a special area in memory where interned strings are stored. It’s separate from the heap memory, which stores objects and dynamically allocated memory.
Memory Management Strategies
Effective memory management involves balancing the use of the string pool and heap memory. Knowing when and how to apply string intern is key to optimizing memory usage.
String Intern in Real-World Scenarios
Let’s explore practical examples of string intern usage and how it can optimize your code.
Use Cases and Examples
- Database Queries: String interning can significantly reduce memory overhead when dealing with database query results that include repeated string values;
- Caching: Implementing string intern in caching mechanisms can lead to faster data retrieval and reduced memory footprint;
- Parsing and Serialization: String intern can improve the efficiency of parsing and serializing data, especially when handling JSON or XML;
- Comparing Strings: When comparing strings for equality, interning can be more efficient than using the equals() method.
Code Optimization Techniques
We’ll also discuss advanced techniques for harnessing the power of string intern in real-world applications.

String Intern Best Practices
To make the most of string intern, follow these best practices:
- Profile Your Application: Measure the impact of string intern in your specific application to ensure it provides tangible benefits;
- Use It Sparingly: Intern only strings that are likely to be repeated frequently, as excessive interning can lead to increased memory usage;
- Monitor Memory Usage: Keep an eye on your application’s memory consumption and adjust string intern usage accordingly.
Advanced String Intern Techniques
For those looking to take their string intern skills to the next level, consider the following advanced techniques:
String Intern for Multithreaded Applications
Learn how to optimize string intern for multithreaded scenarios to ensure thread safety and improved performance.
Custom String Intern Implementations
Explore custom string intern implementations tailored to your specific application requirements.
Conclusion
In this comprehensive guide, we’ve delved deep into the world of string intern in Java 6, 7, and 8. You now have the knowledge to harness the power of string interning, optimize your code, and conserve memory.
Remember to use string intern judiciously, keeping a watchful eye on memory usage, and always measure its impact on your application’s performance.
FAQs
By default, Java 6 automatically interns strings created using double quotes.
You can use the intern() method to manually intern a string in Java.
No, string intern is most beneficial when dealing with repeated string values.
Excessive string intern usage can lead to increased memory consumption, so use it sparingly.
Yes, Java 9 introduced changes to string intern behavior, which are outside the scope of this guide.